Polynomial interpolation
- The simplest form of interpolation function is a polynomial function.
- It is always possible to construct a polynomial of degree that passes through data points.
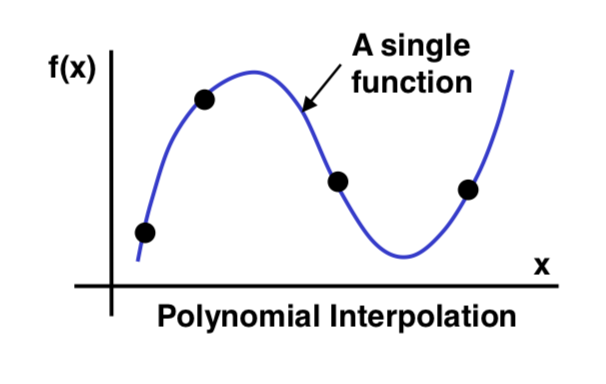
- Linear regression is a simpler case of curve fitting where a straight line is found that fits a set of data points.
- Unlike interpolation, the line need not pass through the points.
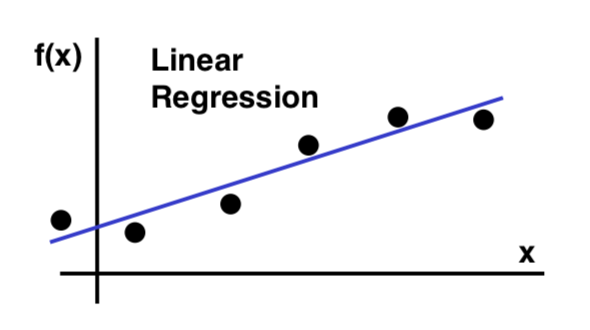
- Linear regression line is given by , where is the slope of the line, and is the y-intercept.
- The main task will be to find and such that the line “fits” the data points in the “best” possible way.
How to determine the “best” fit?
-
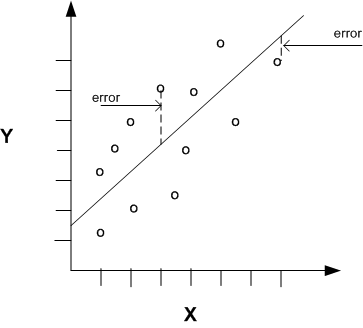
To know how good a line fits the given data points, we compute error for each data point.
-
Error is defined as the squared difference between the actual y-value and the y-value given by the regression line, .
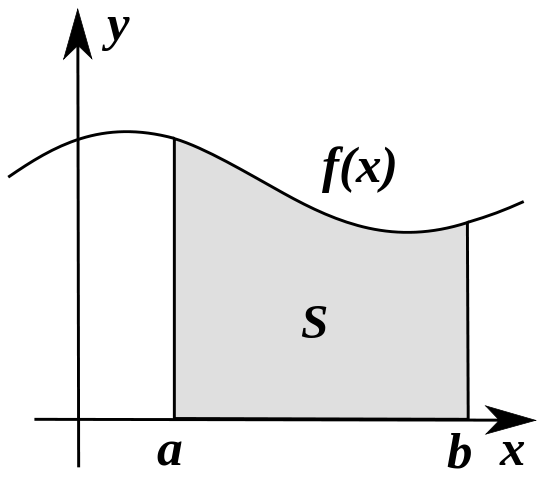
Definite Integral
-
The definite integral of a function of a single variable, , between two limits and can be viewed as the area under the curve.
-
Numerical integration algorithms try to estimate this area
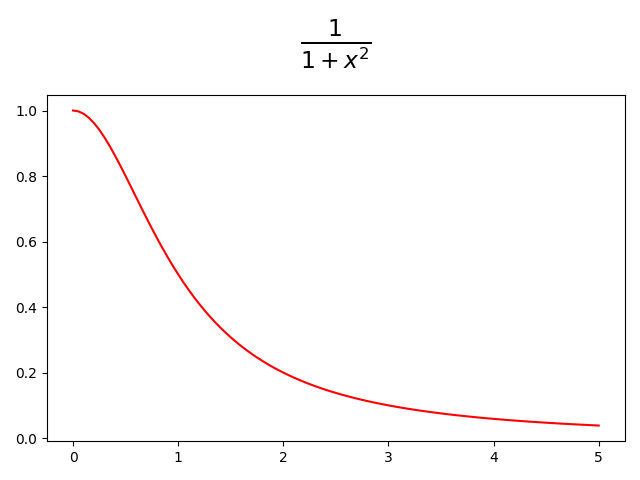
Example
We will use the following function in the interval to compare the three algorithms:
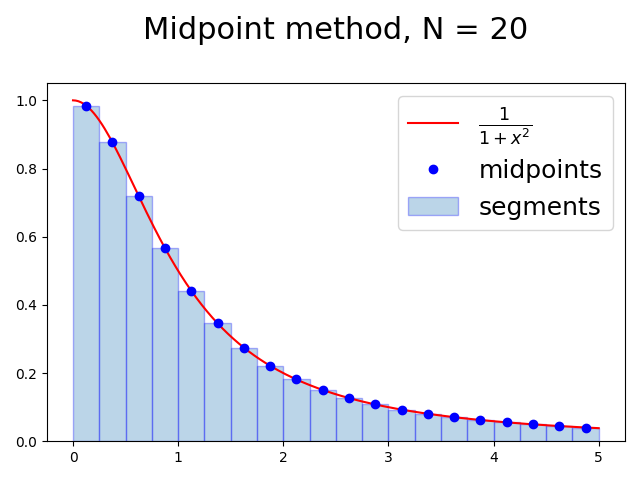
The Midpoint Method
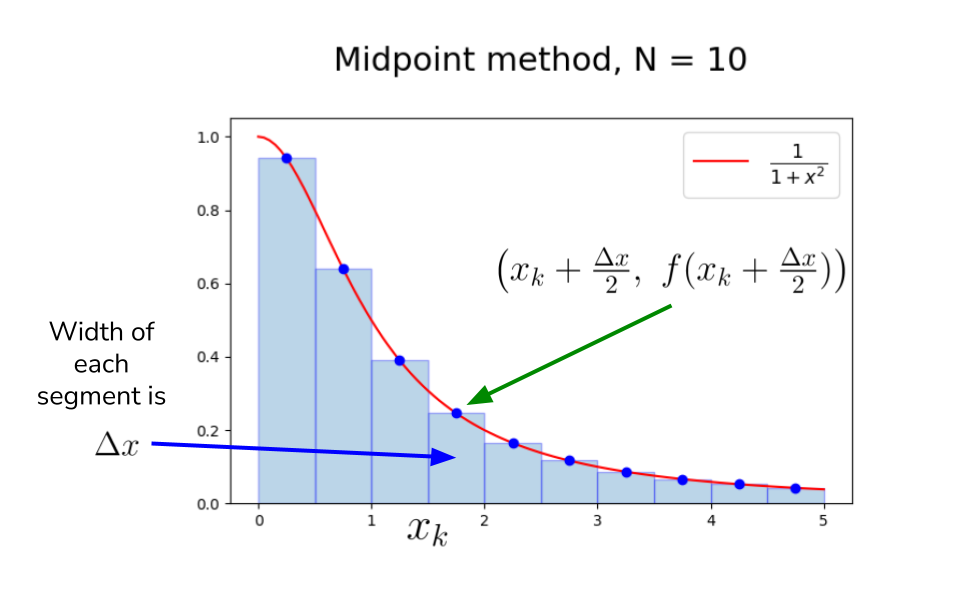
Approximation improves as the number of segments is increased.
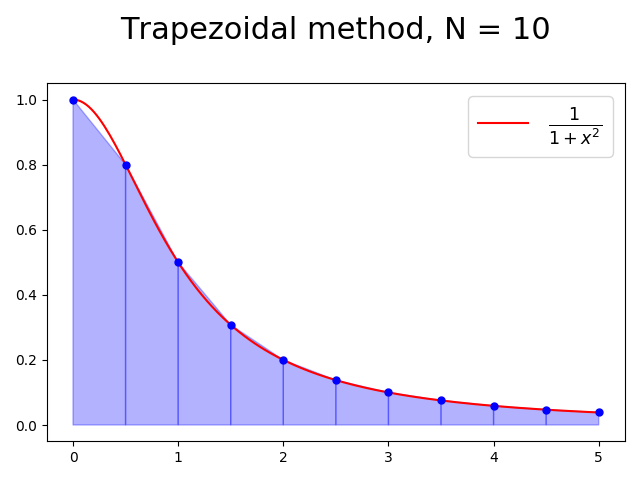
Trapezoidal Method
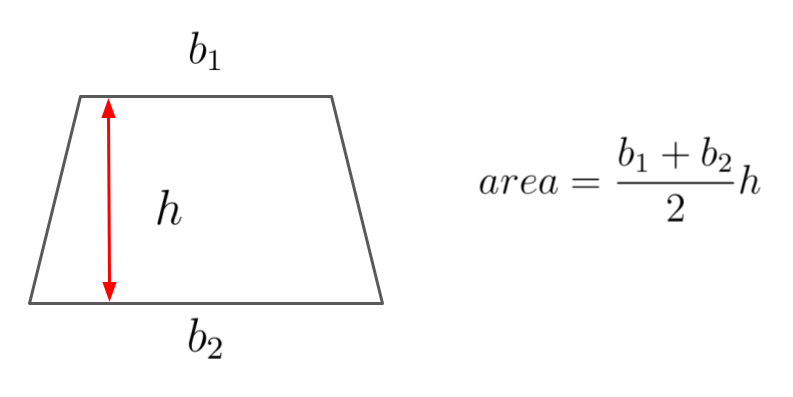
To approximate the area of each segment, use the area of trapezoid rather than the rectangle.
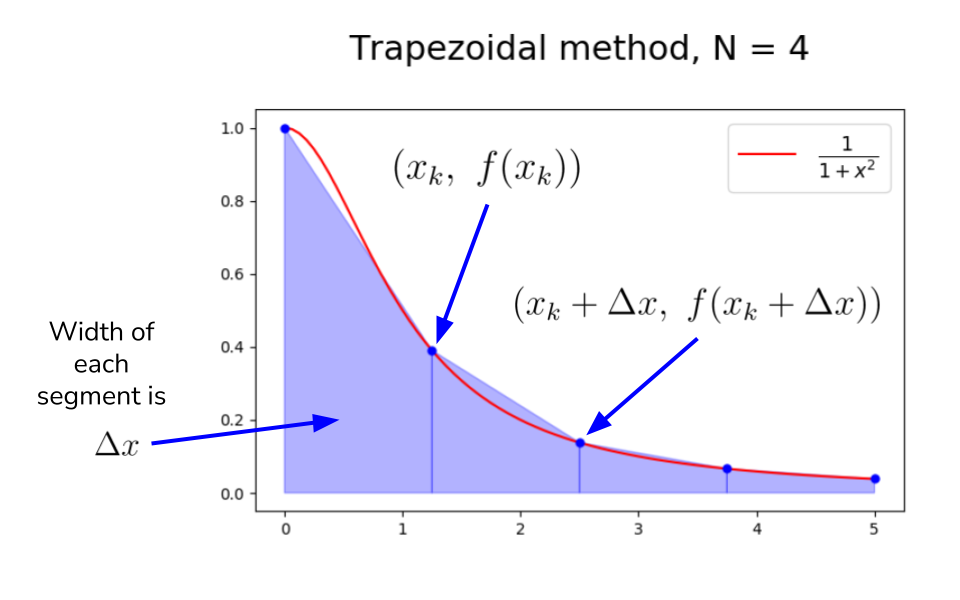
The area of each trapezoidal segment is given by
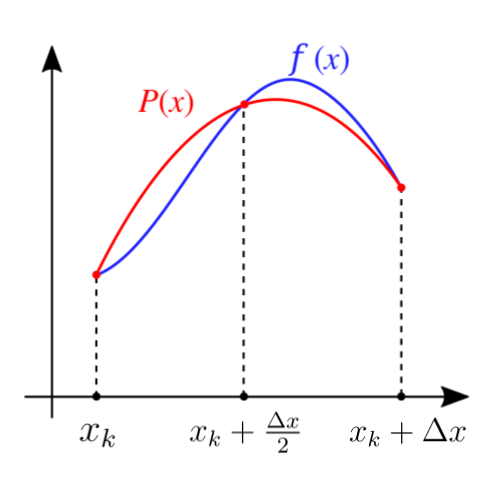
Simpson’s method
Given any three points there is a unique polynomial (parabola), called the interpolating polynomial, that passes through these points
Integration using scipy.integrate
Check scipy_integrate.py file on Ed.
